Содержание
17 декабря состоялся День Открытых Дверей Института Энергетики!
Мы были рады приветствовать всех заинтересованных абитуриентов и их родителей.
Программа Дня Открытых Дверей началась прямо у Дирекции ИЭ — будущие студенты подходили к представителям каждого направления и задавали свои вопросы. Благодаря отзывчивости адаптеров и преподавателей, у ребят появилось первое представление об изучаемых дисциплинах, условиях, практике и трудоустройстве.
Фотограф Виктория Кудюмова
Затем, в большой лекционной аудитории, начались выступления Ирины Евгеньевны Рындиной и Максима Валерьевича Конюшина — они рассказали о правилах приёма, изменениях и о самом Институте. Далее, мы услышали информацию о каждой Высшей Школе ИЭ: Александр Антонович Калютик и Андрей Павлович Плотников представили ВШАиТЭ и ВШВЭ, Иванов Дмитрий Владимирович и Алёна Сергеевна Алёшина, познакомили присутствующих с ВШЭС и ВШЭМ, а Николай Александрович Катанаха, как выпускник, а теперь уже доцент ИЭ, поделился своим опытом обучения и дальнейшей работы.
Далее абитуриентов поделили на две группы, чтобы пройти по заранее подготовленным маршрутам — кто-то отправился с Потоком «Энергичный», а другие — с потоком «Светлый».
Остановка — ФабЛаб
Фотограф Виктория Кудюмова
Представители Высшей Школы Энергетического Машиностроения использовали весь потенциал Точки Кипения в Башне Политеха, чтобы заинтересовать ребят. Лицо, а точнее лица, ВШЭМ — это молодые и заряженные сотрудники, которые постарались рассказать, что ожидает тех, кто захочет поступить к ним. О самом направлении мы узнали от Директора, Алёны Сергеевны Алёшиной, а своих проектах и деятельности рассказали Арсентий Сергеевич Клюев, Михаил Александрович Лаптев, Алексей Михайлович Яблоков, Андрей Александрович Метелев. Рассказать — это одно, а вот показать — это совсем другое. Ребята смогли поближе рассмотреть учебные макеты, а также двухконтурный турбореактивный двигатель для истребителя МИГ-29 — пожалуй, это зажгло искру в глазах у некоторых гостей и они сразу же завалили выступающих вопросами.
Тайны Лаборатории ТЭУ
Фотограф — Виктория Кудюмова
На улице уже стемнело, когда поток абитуриентов отправился на следующую станцию. Там их приветствовала Эльза Рафисовна Зайнуллина, доцент ВШАиТЭ, и разъяснила некоторые аспекты обучения и работы «тепловиков». Она и Павел Геннадьевич Бобылев показали оборудование в лабораториях Технической термодинамики и Тепломассообмена, объяснили, что это за зверь такой — «лабы» и с чем их выполняют. Владимир Викторович Сероштанов, в свою очередь, увлёк присутствующих в Лаборатории теплообмена и аэродинамики — они внимательно слушали рассказчиков и наблюдали за показанными экспериментами.
Мы ТОЭ заинтересованы
Фотограф — Виктория Кудюмова
Предпоследней остановкой была Лаборатория ТОЭ — там проводниками стали Александр Гелиевич Калимов и Дмитрий Владимирович Иванов. Они буквально «показали» историю — в лаборатории есть примеры устройств из прошлых веков, которые до сих пор дают точные показания, не отставая от своих более инновационных собратьев. Что значит быть «электриком» и чему они участся в Политехе? Теперь на этот вопрос у будущих студентов есть ответ.
Что значит быть «электриком» и чему они участся в Политехе? Теперь на этот вопрос у будущих студентов есть ответ.
«Last but not least» — Перегрузочная машина ядерного реактора
Фотограф — Виктория Кудюмова
У «атомщиков» была своя атмосфера — Максим Валерьевич Конюшин, старший преподаватель ВШАиТЭ, встретил потенциальных студентов в полном вооружении. Рассказав, что ожидает всех, кто решил изучать ядерную энергетику, он дал слово студентам этого направления. Они ответили на вопросы о том, как они учатся и чем занимаются. Помимо этого, был продемонстрирован проект перегрузочной машины, полностью созданный на 3D-принтере студентами, под руководством преподавателей.
Такой активный подход был захватывающим завершением не менее захватывающего дня.
Следующий День Открытых Дверей уже скоро — 21 января свои двери откроет ВШЭМ — следите за новостями у нас ВКонтакте или в Телеграме.
Фотографии с ДОД можно посмотреть здесь — vk.cc/cjUlDH
Пресс-релиз подготовлен Медиа-центром ИЭ.
Благодарим Ирину Евгеньевну Рындину, Викторию Кудюмову, Анастасию Буровцеву за помощь в освещении мероприятия.
Поделиться записью
Фриланс и удаленная работа – Freelancehunt, лучший сервис фриланса и вакансий для удаленной работы фрилансера в Украине
На бирже Freelancehunt более 1485 открытых фриланс проектов для удаленной работы фрилансеру. Каждый фрилансер сможет найти подходящий проект по своей специализации.
Кто может стать фрилансером
Тексты, программирование, верстка, дизайн, оптимизация сайта это лишь немногие заказы и вакансии, которые предлагает наша биржа Freelancehunt. На площадке вы также можете ознакомиться с полезной информацией, например, узнать статистику цен по вакансиям онлайн. Брать заказы могут как фрилансеры Киева, так и жители всей Украины и других стран. Здесь нет территориальных ограничений, заняться фрилансом может каждый желающий, кто ищет заказы на дому.
Как начать работать на фрилансе
Если вы решили стать удаленным фрилансером и работать на дому, определитесь, над какими проектами будете трудиться.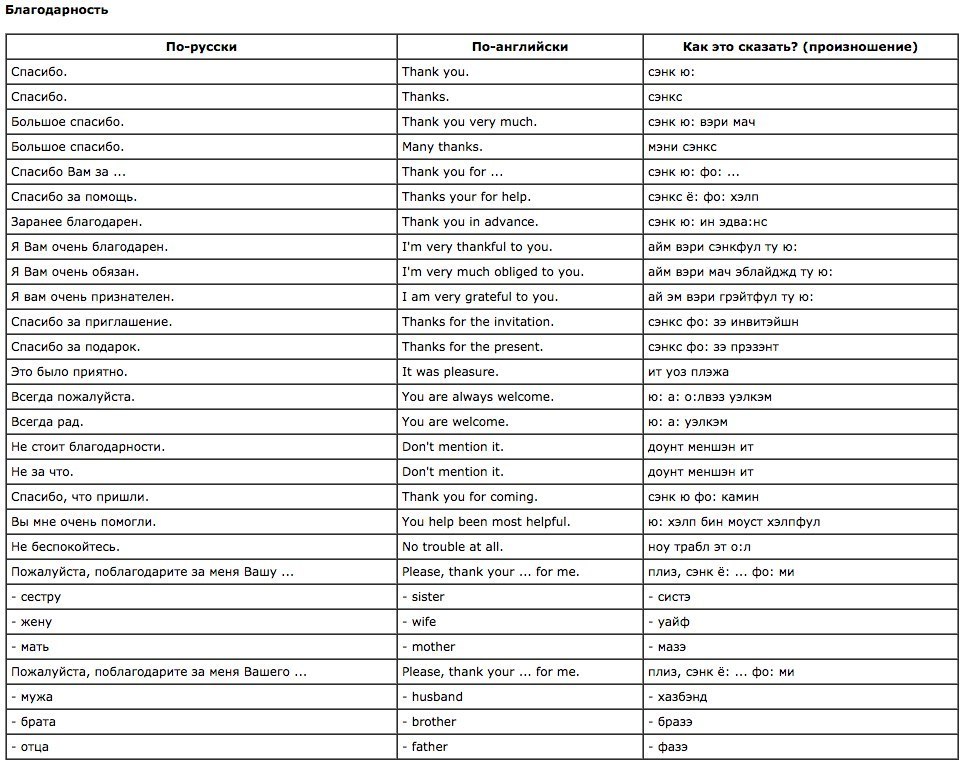 Для поиска успешной работы важно создание качественного портфолио. Если вы фрилансер без опыта, сделайте для демонстрации возможностей несколько работ по вашей специфике и начинайте искать подработку на дому в активных конкурсах на нашей бирже.
Для поиска успешной работы важно создание качественного портфолио. Если вы фрилансер без опыта, сделайте для демонстрации возможностей несколько работ по вашей специфике и начинайте искать подработку на дому в активных конкурсах на нашей бирже.
Уровень оплаты фрилансера
Сколько будет зарабатывать специалист freelance, зависит от многих факторов. На уровень дохода влияет специализация, наличие навыков и опыта. Новички обычно ищут низкие по цене проекты, постепенно расширяя портфолио. Профессионалы со стажем, особенно занятые в IT-сфере специалисты Python на фриланс-работе, самые высокооплачиваемые как в Киеве, так и по всей Украине.
Где фрилансеру найти работу
Работа на freelance связана с интернетом. Именно там в режиме онлайн и встречаются заказчик с исполнителем. Связующим звеном становятся биржи. Конечно, можно заниматься поиском подработки самостоятельно, но в таком случае обязательно берите предоплату. Или же сотрудничайте с нашей биржей Freelancehunt крупнейшей площадкой в интернете, где можно искать любые фриланс заказы.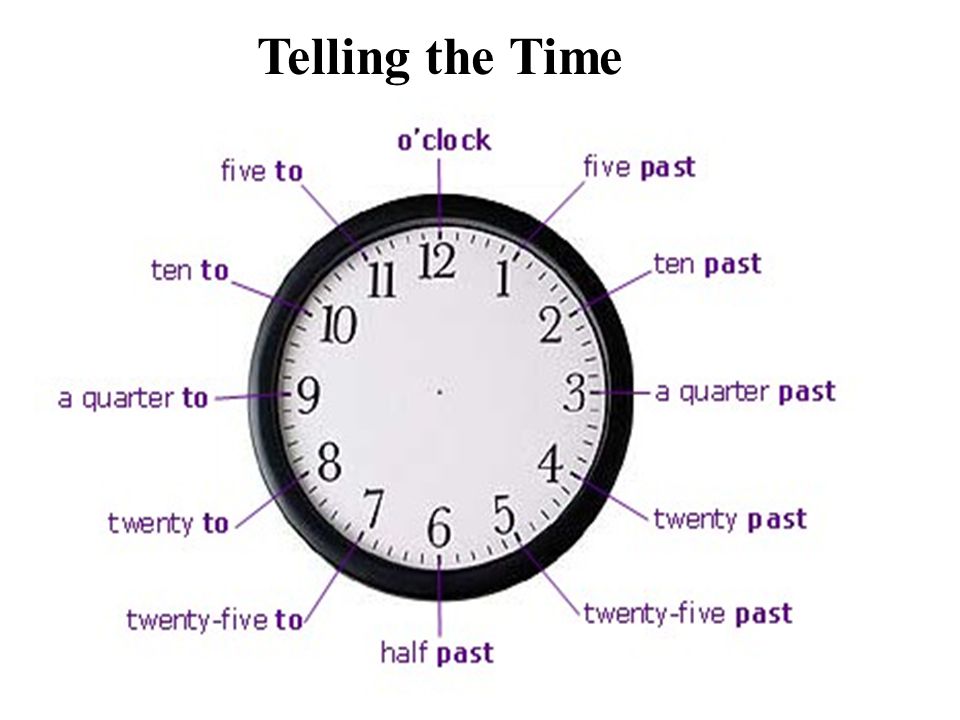
Чтобы стать фрилансером у нас, выполните следующие шаги:
- Зарегистрируйтесь.
- Заполните свой профиль.
- Наполните портфолио готовыми работами.
- Начинайте искать и брать в работу заказы.
Напишите на своей странице «Ищу работу», чтобы заказчики знали, что к вам можно обращаться.
Большое преимущество нашего сайта возможность начинать свою деятельность на фрилансе новичкам, ведь не все заказчики готовы сотрудничать с еще неопытными исполнителями. На площадке Freelancehunt можно найти задачи, ориентированные на тех, кто только вступает в ряды фрилансеров Украины.
Фриланс работа на дому
Какая средняя стоимость выполнения проекта на Freelancehunt?
Стоимость работы формируется заказчиком либо фрилансер может самостоятельно указать свою цену за выполнение работы. Цена реализации проекта зависит от необходимых навыков и трудозатрат.
Сколько заказчиков на бирже фриланса?
В данный момент на Freelancehunt более 80 000 заказчиков.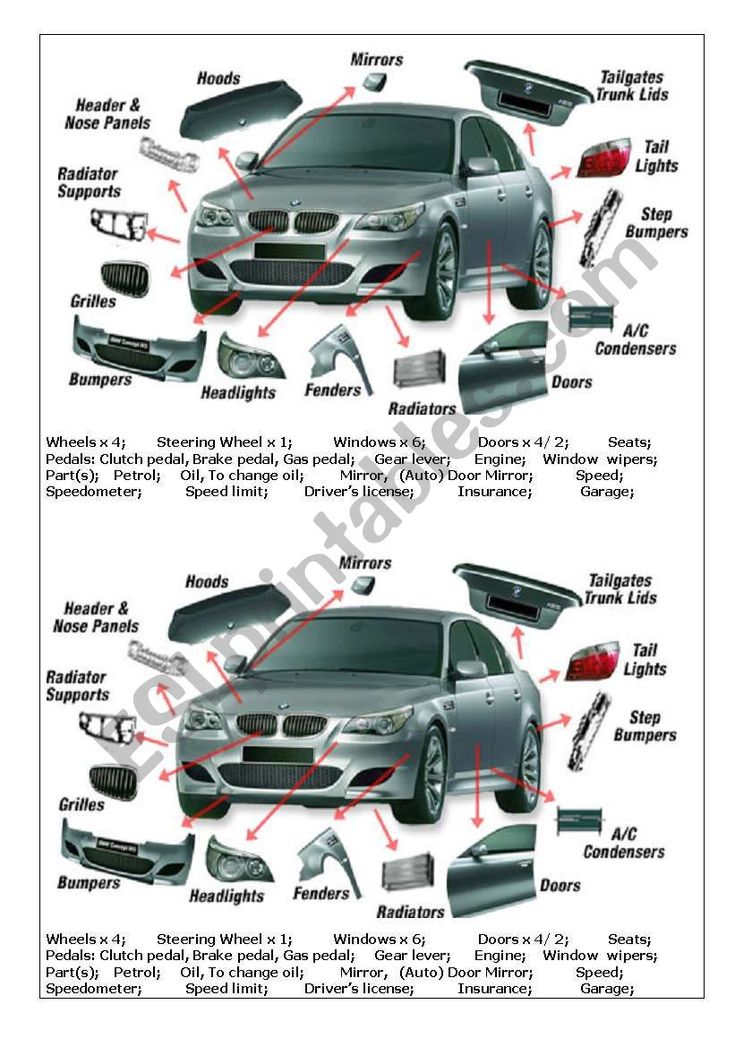
Сколько всего проектов доступно на бирже?
Сейчас на бирже Freelancehunt более 1700 активных проектов.
Представляем первую модель ИИ, которая переводит на 100 языков, не полагаясь на английский
- Facebook AI представляет M2M-100, первую модель многоязычного машинного перевода (MMT), которая может переводить между любой парой 100 языков, не полагаясь на данные на английском языке. Это с открытым исходным кодом здесь.
- При переводе, скажем, с китайского на французский, большинство англо-ориентированных многоязычных моделей тренируются с китайского на английский и с английского на французский, поскольку данные для обучения на английском языке являются наиболее широко доступными. Наша модель напрямую обучает данные с китайского на французский, чтобы лучше сохранить смысл. Он превосходит англо-ориентированные системы на 10 баллов по широко используемой метрике BLEU для оценки машинных переводов.
- M2M-100 обучается в общей сложности 2200 языковым направлениям — или в 10 раз больше, чем предыдущие лучшие многоязычные модели, ориентированные на английский язык.
 Развертывание M2M-100 улучшит качество переводов для миллиардов людей, особенно для тех, кто говорит на малоресурсных языках.
Развертывание M2M-100 улучшит качество переводов для миллиардов людей, особенно для тех, кто говорит на малоресурсных языках. - Эта веха является кульминацией многолетней фундаментальной работы искусственного интеллекта Facebook в области машинного перевода. Сегодня мы делимся подробностями о том, как мы создали более разнообразный набор данных для обучения MMT и модель для 100 языков. Мы также выпускаем модель, систему обучения и оценки, чтобы помочь другим исследователям воспроизвести и усовершенствовать многоязычные модели.
 Развертывание M2M-100 улучшит качество переводов для миллиардов людей, особенно для тех, кто говорит на малоресурсных языках.
Развертывание M2M-100 улучшит качество переводов для миллиардов людей, особенно для тех, кто говорит на малоресурсных языках. Преодоление языковых барьеров с помощью машинного перевода (MT) — один из наиболее важных способов объединить людей, предоставить достоверную информацию о COVID-19 и защитить их от вредоносного контента. Сегодня мы ежедневно выполняем в среднем 20 миллиардов переводов в ленте новостей Facebook благодаря нашим последним разработкам в области машинного перевода с низким уровнем ресурсов и недавним достижениям в области оценки качества перевода.
Типичные системы машинного перевода требуют создания отдельных моделей ИИ для каждого языка и каждой задачи, но этот подход неэффективно масштабируется на Facebook, где люди размещают контент на более чем 160 языках в миллиардах сообщений. Усовершенствованные многоязычные системы могут обрабатывать несколько языков одновременно, но снижают точность, полагаясь на данные на английском языке для преодоления разрыва между исходным и целевым языками. Нам нужна одна модель многоязычного машинного перевода (MMT), которая может переводить любой язык, чтобы лучше обслуживать наше сообщество, почти две трети которого используют язык, отличный от английского.
В результате многолетних исследований машинного перевода в Facebook мы рады объявить об важной вехе: первой единой массовой модели MMT, которая может напрямую переводить 100 × 100 языков в любом направлении, не полагаясь только на англо-ориентированные данные. Наша единая многоязычная модель работает так же хорошо, как и традиционные двуязычные модели, и добилась улучшения на 10 баллов по шкале BLEU по сравнению с англоязычными многоязычными моделями.
Используя новые стратегии интеллектуального анализа данных для создания данных перевода, мы создали первый набор данных «многие ко многим» с 7,5 миллиардами предложений для 100 языков. Мы использовали несколько методов масштабирования, чтобы построить универсальную модель с 15 миллиардами параметров, которая собирает информацию из родственных языков и отражает более разнообразный сценарий языков и морфологию. Мы открываем исходный код этой работы здесь.
Извлечение сотен миллионов предложений для тысяч языковых направлений
Одним из самых больших препятствий при построении модели MMT «многие ко многим» является курирование больших объемов качественных пар предложений (также известных как параллельные предложения) для произвольных направлений перевода, а не с участием английского языка. Гораздо проще найти переводы с китайского на английский и с английского на французский, чем, скажем, с французского на китайский. Более того, объем данных, необходимых для обучения, растет квадратично с количеством поддерживаемых языков. Например, если нам нужно 10 миллионов пар предложений для каждого направления, нам нужно добыть 1 миллиард пар предложений для 10 языков и 100 миллиардов пар предложений для 100 языков.
Мы взяли на себя эту амбициозную задачу по созданию самого разнообразного набора данных MMT «многие ко многим» на сегодняшний день: 7,5 миллиардов пар предложений на 100 языках. Это стало возможным благодаря объединению дополнительных ресурсов интеллектуального анализа данных, которые разрабатывались годами, включая ccAligned, ccMatrix и LASER. В рамках этих усилий мы создали новый LASER 2.0 и улучшили идентификацию языка fastText, что повышает качество майнинга и включает сценарии обучения и оценки с открытым исходным кодом. Все наши ресурсы интеллектуального анализа данных используют общедоступные данные и имеют открытый исходный код.
Новая многоязычная модель Facebook AI «многие ко многим» является кульминацией нескольких лет новаторской работы в области машинного перевода с использованием революционных моделей, ресурсов интеллектуального анализа данных и методов оптимизации. На этой временной шкале отмечены несколько заслуживающих внимания достижений. Кроме того, мы создали наш массивный набор данных для обучения путем майнинга ccNET, основанного на fastText , нашей новаторской работе по обработке представлений слов; наша библиотека LASER для CCMatrix, которая встраивает предложения в многоязычное пространство для встраивания; и CCAligned, наш метод выравнивания документов на основе совпадений URL-адресов. В рамках этих усилий мы создали LASER 2.0, который улучшает предыдущие результаты.
Тем не менее, даже с передовыми базовыми технологиями, такими как LASER 2.0, сбор крупномасштабных обучающих данных для произвольных пар 100 различных языков (или 4450 возможных языковых пар) требует больших вычислительных ресурсов. Чтобы сделать этот тип масштабирования майнинга более управляемым, мы сначала сосредоточились на языках с наибольшим количеством запросов на перевод. Следовательно, мы отдали предпочтение направлениям майнинга с данными самого высокого качества и наибольшим количеством данных. Мы избегали направлений, для которых потребность в переводе статистически редка, таких как исландский-непальский или сингальский-яванский.
Затем мы представили новую стратегию поиска мостов, в которой мы группируем языки в 14 языковых групп на основе лингвистической классификации, географии и культурных сходств. Люди, живущие в странах с языками одной семьи, как правило, общаются чаще, и им нужны качественные переводы. Например, одна группа будет включать языки, на которых говорят в Индии, такие как бенгальский, хинди, маратхи, непальский, тамильский и урду. Мы систематически изучили все возможные языковые пары внутри каждой группы.
Чтобы соединить языки разных групп, мы определили небольшое количество промежуточных языков, которые обычно представляют собой от одного до трех основных языков каждой группы. В приведенном выше примере хинди, бенгальский и тамильский языки были бы промежуточными языками для индоарийских языков. Затем мы изучили данные параллельного обучения для всех возможных комбинаций этих промежуточных языков. Используя эту технику, наш обучающий набор данных получил 7,5 миллиардов параллельных предложений данных, соответствующих 2200 направлениям. Поскольку добытые данные можно использовать для обучения двух направлений заданной языковой пары (например, en->fr и fr->en), наша стратегия добычи помогает нам эффективно разреженно добывать данные, чтобы наилучшим образом охватить все 100×100 (всего 9 языков).,900) направлений в одной модели.
Чтобы дополнить параллельные данные для малоресурсных языков с низким качеством перевода, мы использовали популярный метод обратного перевода, который помог нам занять первые места на конкурсах WMT International Machine Translation 2018 и 2019 годов. Например, если наша цель — обучить модель перевода с китайского на французский, мы сначала обучим модель для французского на китайский и переведем все одноязычные французские данные для создания синтетического китайского с обратным переводом. Мы обнаружили, что этот метод особенно эффективен в больших масштабах при переводе сотен миллионов одноязычных предложений в параллельные наборы данных. В наших условиях исследования мы использовали обратный перевод, чтобы дополнить обучение направлений, которые мы уже изучили, добавив синтетические данные обратного перевода к добытым параллельным данным. И мы использовали обратный перевод для создания данных для ранее неконтролируемых направлений.
В целом, сочетание нашей стратегии моста и данных с обратным переводом улучшило производительность по 100 направлениям с обратным переводом в среднем на 1,7 BLEU по сравнению с обучением только на добытых данных. Благодаря более надежному, эффективному и высококачественному обучающему набору у нас была хорошая основа для построения и масштабирования нашей модели «многие ко многим».
Мы также получили впечатляющие результаты при нулевых настройках, в которых отсутствуют обучающие данные для пары языков. Например, если модель обучена французско-английскому и немецко-шведскому языкам, мы можем выполнить нулевой перевод между французским и шведским языками. В условиях, когда наша модель «многие ко многим» должна обнулить перевод между направлениями, не относящимися к английскому языку, она была значительно лучше, чем многоязычные модели, ориентированные на английский язык.
Масштабирование нашей модели MMT до 15 миллиардов параметров с высокой скоростью и качеством
Одной из проблем при многоязычном переводе является то, что единая модель должна фиксировать информацию на многих разных языках и в различных сценариях. Чтобы решить эту проблему, мы увидели явное преимущество в масштабировании возможностей нашей модели и добавлении параметров, зависящих от языка. Масштабирование размера модели полезно, в частности, для языковых пар с высоким уровнем ресурсов, поскольку они содержат больше всего данных для обучения дополнительной емкости модели. В конечном итоге мы увидели среднее улучшение в 1,2 BLEU, усредненное по всем языковым направлениям, при плотном масштабировании размера модели до 12 миллиардов параметров, после чего наблюдалось уменьшение отдачи от дальнейшего плотного масштабирования. Сочетание плотного масштабирования и разреженных параметров для конкретного языка (3,2 миллиарда) позволило нам создать еще лучшую модель с 15 миллиардами параметров.
Мы сравниваем нашу модель с базовыми двуязычными и англоязычными многоязычными моделями. Мы начинаем с 1,2 миллиарда базовых параметров с 24 слоями кодировщика и 24 слоями декодера и сравниваем англо-ориентированные модели с нашей моделью M2M-100. Далее, если мы сравним 12 миллиардов параметров с 1,2 миллиардами параметров, мы получим улучшение на 1,2 балла BLEU.
Чтобы увеличить размер нашей модели, мы увеличили количество слоев в наших сетях Transformer, а также ширину каждого слоя. Мы обнаружили, что большие модели быстро сходятся и обучаются с высокой эффективностью данных. Примечательно, что эта система «многие ко многим» является первой, использующей Fairscale, новую библиотеку PyTorch, специально разработанную для поддержки конвейерного и тензорного параллелизма. Мы построили эту общую инфраструктуру для размещения крупномасштабных моделей, которые не помещаются на одном графическом процессоре, за счет параллелизма моделей в Fairscale. Мы создали оптимизатор ZeRO, внутриуровневый параллелизм моделей и параллелизм конвейерных моделей для обучения крупномасштабных моделей.
Но недостаточно просто масштабировать модели до миллиардов параметров. Чтобы иметь возможность производить эту модель в будущем, нам необходимо максимально эффективно масштабировать модели с помощью высокоскоростного обучения. Например, во многих существующих работах используется мультимодельный ансамбль, когда несколько моделей обучаются и применяются к одному и тому же исходному предложению для получения перевода. Чтобы уменьшить сложность и объем вычислений, необходимых для обучения нескольких моделей, мы изучили самостоятельную сборку из нескольких источников, которая переводит исходное предложение на несколько языков для повышения качества перевода. Кроме того, мы опирались на нашу работу с LayerDrop и Depth-Adaptive для совместного обучения модели с общим стволом и различными наборами языковых параметров. Этот подход отлично подходит для моделей «многие ко многим», поскольку он предлагает естественный способ разделения частей модели по языковым парам или языковым семьям. Комбинируя плотное масштабирование емкости модели с параметрами, зависящими от языка (всего 3 миллиарда), мы предоставляем преимущества больших моделей, а также возможность изучения специализированных слоев для разных языков.
На пути к одной многоязычной модели для всех
В течение многих лет исследователи искусственного интеллекта работали над созданием единой универсальной модели, способной понимать все языки при выполнении различных задач. Единая модель, поддерживающая все языки, диалекты и модальности, поможет нам лучше обслуживать больше людей, обновлять переводы и в равной степени создавать новые впечатления для миллиардов людей. Эта работа приближает нас к этой цели.
В рамках этих усилий мы наблюдаем невероятно быстрый прогресс в предварительно обученных языковых моделях, тонкой настройке и методах самоконтроля. Это коллективное исследование может еще больше улучшить то, как наша система понимает текст для языков с низким уровнем ресурсов, используя немаркированные данные. Например, XLM-R — это наша мощная многоязычная модель, которая может обучаться на основе данных на одном языке, а затем выполнять задачу на 100 языках с высочайшей точностью. mBART — это один из первых методов предварительной подготовки полной модели для выполнения задач BART на многих языках. А совсем недавно наш новый подход с самоконтролем, CRISS, использует немаркированные данные из множества разных языков для анализа параллельных предложений на разных языках и обучения новых, более совершенных многоязычных моделей итеративным способом.
Мы продолжим улучшать нашу модель, используя передовые исследования, изучая способы ответственного развертывания систем машинного перевода и создавая более специализированные вычислительные архитектуры, необходимые для внедрения этого в производство.
16 онлайн-инструментов для перевода, рекомендованных переводчиками
Примечание редактора: этот пост был первоначально опубликован в мае 2016 г. и обновлен в октябре 2019 г.
требует обширных исследований и контекстуальных знаний. К счастью, цифровая революция привела к созданию инструментов, программного обеспечения и ресурсов, которые помогают упростить перевод и повысить эффективность, согласованность и качество. Ниже приведен список инструментов перевода, рекомендуемых переводчиками для переводчиков.
1. Linguee
Этот уникальный инструмент перевода, полюбившийся многим, сочетает в себе словарь и поисковую систему, поэтому вы можете искать двуязычные тексты, слова и выражения на разных языках, чтобы проверять значения и контекстуальные переводы. Linguee также ищет в Интернете соответствующие переведенные документы и показывает, как слово переводится в Интернете. Он часто используется вместе с Google Images, чтобы помочь как переводчикам, так и изучающим языки.
2. SDL Trados Studio
SDL Trados, наиболее рекомендуемый инструмент автоматизированного перевода (CAT) от Gengo Wordsmiths, является разумным вложением для штатных переводчиков. Это программное обеспечение включает в себя ТМ, терминологию, машинный перевод и локализацию программного обеспечения. Большинству крупных агентств требуется, чтобы переводчики работали с одним из установленных CAT-инструментов, поэтому использование SDL Trados также может увеличить вашу клиентскую базу и расширить кругозор. Если вам нужно время, чтобы определиться перед покупкой, попробуйте бесплатную демо-версию на 30 дней.
3. Бесплатный словарь
Доступный на самых разных языках, этот обширный сайт представляет собой словарь, тезаурус и энциклопедию в одном флаконе. Получите бесплатный доступ к медицинским, финансовым и юридическим словарям, обширной коллекции идиом, акронимов, цитат и нескольких языков помимо английского, таких как испанский, французский, португальский и японский. В энциклопедии также регулярно обновляются разделы, предоставляющие пользователям слово или статью дня. Бесплатное мобильное приложение совместимо с устройствами iOS и Android.
4.
Fluency Now
Fluency Now Professional — это CAT-инструмент премиум-класса и программное обеспечение памяти переводов, созданное для отдельных фрилансеров. Доступный за 9,95 долларов в месяц, он совместим с операционными системами Mac, Windows и Linux. Для организаций Fluency Now Enterprise предоставляет доступ к дополнительным функциям, таким как Fluency Flow, решение для управления проектами. Он также предоставляет встроенное программное обеспечение для корректуры и статистику проектов и документов.
5. ProZ
Если вы предпочитаете взаимодействие и краудсорсинг, ProZ должен стать вашим ресурсом. ProZ является домом для крупнейшей в мире переводческой сети. Это портал для профессиональных переводчиков, которые хотят сотрудничать в области перевода терминов, словарей, обучения, а также получить доступ к скидкам на инструменты для перевода. Переводчики также могут задавать вопросы и участвовать в дискуссиях на форуме.
6. MemoQ
Программное обеспечение для перевода MemoQ, предназначенное для переводчиков-фрилансеров, предлагает ряд мощных функций, позволяющих повторно использовать предыдущие переводы. Он также имеет функции, помогающие улучшить качество, проверить согласованность и обеспечить использование правильной терминологии. Версия 2015 года также имеет более быструю функцию проверки орфографии. Проверьте, работает ли это для вас, попробовав бесплатную демо-версию в течение 45 дней.
7. Memsource
База данных TM, интегрированная с Gengo для повышения эффективности. Memsource представляет собой облачную среду перевода, которая обеспечивает эффективный и действенный инструмент управления проектами. Пользователи могут дополнительно оптимизировать свою производительность перевода, используя такие функции, как TM, редактирование и управление терминологией в рамках платформы.
8. Кафе переводчиков
Интернет-сообщество и форум, где вы можете задать вопросы и дать совет опытным переводчикам. Регистрация бесплатна как для профессиональных переводчиков, так и для переводчиков-любителей, и члены Translators Café могут делать ставки и находить работу без дополнительной платы. Работодатели могут связаться с фрилансерами на основе их предложений или предоставить свою информацию переводчикам. Платежи выплачиваются напрямую фрилансерам без счетов условного депонирования.
9. Zanata
Веб-система для переводчиков, создателей контента и разработчиков для управления проектами локализации. Zanata управляет всем рабочим процессом перевода и позволяет переводчикам сосредоточиться на переводах, а не на инструментах и форматах. Его ТМ также находит и предлагает лучшие совпадения перевода во всей системе. Редактор Zanata работает в любом веб-браузере без необходимости установки. Несколько переводчиков также могут работать в редакторе с чатом для общения в режиме реального времени.
10. WordFast Pro
Wordfast Pro — это автономный многоплатформенный инструмент TM, предназначенный для улучшения процесса перевода для всех, от менеджеров проектов до переводчиков-фрилансеров. В отличие от других CAT-инструментов, переводчики могут импортировать и экспортировать ПП даже в демо-версии и могут использоваться неограниченное время. Единственным ограничением является размер памяти переводов (500 единиц). Нет необходимости доплачивать за учебные пособия и поддержку, и они обеспечивают отличную поддержку клиентов.
11. SmartCAT
Инструмент CAT для совместной работы SmartCAT упрощает процесс перевода, позволяя переводчику, редактору и другим участникам работать и сотрудничать в режиме реального времени. Это облачное программное обеспечение использует концепцию памяти переводов (TM) и позволяет переводчикам создавать глоссарии для согласованных переводов. Кроме того, SmartCAT теперь поддерживает многоязычные памяти переводов, что упрощает создание и управление НП по сравнению с некоторыми настольными приложениями. Эта функция также может быть полезна переводчикам, работающим в смешанных языковых парах.
12. Magic Search
Для более быстрого поиска по терминологии Magic Search представляет собой многоязычную поисковую систему, предоставляющую результаты поиска на одной странице по нескольким словарям и другим источникам для разных языковых пар. Он выполняет поиск по нескольким источникам, таким как Word Reference, TAUS, IETA, EUdict и другим. Пользователи также могут установить расширение Google Chrome в свой браузер и настроить список словарей и источников, которые они хотели бы искать.
13. IATE (Интерактивная терминология для Европы)
Запущенная в 1999 году, IATE (расшифровывается как Interactive Terminology for Europe) является межведомственной терминологической базой данных Европейского Союза. Этот полезный ресурс обеспечивает согласованность и качество всех письменных сообщений, связанных с ЕС. Он играет жизненно важную роль для переводчиков и лингвистов, поскольку охватывает все 23 официальных европейских языка и содержит 8,4 миллиона терминов, характерных для ЕС, 540 000 сокращений и 130 000 фраз. Пользователи могут оценить надежность терминов, которые вносят в базу данных терминологи и переводчики ЕС.
14. Языковой портал Microsoft
Для переводчиков, специализирующихся в области ИТ и программного обеспечения, языковой портал Microsoft позволяет пользователям искать переводы ключевых терминов Microsoft и общей терминологии ИТ. База терминов содержит около 25 000 определенных терминов, включая определения на английском языке, переведенные на 100 языков. Пользователи также могут загрузить коллекцию терминологии Microsoft, содержащую стандартные термины терминологии, используемые в продуктах Microsoft, а также переводы пользовательского интерфейса, руководства по стилю Microsoft и API службы терминологии Microsoft.
15. OmegaT
OmegaT — бесплатный инструмент памяти переводов. Это программное обеспечение с открытым исходным кодом позволяет переводчикам работать более эффективно за счет нечеткого сопоставления (компьютерного перевода) и автоматического распространения совпадений. Этот инструмент также использует несколько памяти переводов одновременно и позволяет пользователям одновременно обрабатывать несколько файловых проектов. Его мощные инструменты включают поддержку Unicode (UTF-8), которую можно использовать с нелатинскими алфавитами; встроенная проверка орфографии и совместимость с другими приложениями памяти переводов.